来源:自学PHP网 时间:2015-04-17 12:00 作者: 阅读:次
[导读] Cross-SiteRequestForgery(CSRF),中文一般译作跨站请求伪造。经常入选owasp漏洞列表Top10,在当前web漏洞排行中,与XSS和SQL注入并列前三。与前两者相比,CSRF相对来说受到的关注要小很多,...
Cross-Site Request Forgery(CSRF),中文一般译作跨站请求伪造。经常入选owasp漏洞列表Top10,在当前web漏洞排行中,与XSS和SQL注入并列前三。与前两者相比,CSRF相对来说受到的关注要小很多,但是危害却非常大。通常情况下,有三种方法被广泛用来防御CSRF攻击:验证token,验证HTTP请求的Referer,还有验证XMLHttpRequests里的自定义header。鉴于种种原因,这三种方法都不是那么完美,各有利弊。 二 CSRF的分类在跨站请求伪造(CSRF)攻击里面,攻击者通过用户的浏览器来注入额外的网络请求,来破坏一个网站会话的完整性。而浏览器的安全策略是允许当前页面发送到任何地址的请求,因此也就意味着当用户在浏览他/她无法控制的资源时,攻击者可以控制页面的内容来控制浏览器发送它精心构造的请求。 1、网络连接。例如,如果攻击者无法直接访问防火墙内的资源,他可以利用防火墙内用户的浏览器间接的对他所想访问的资源发送网络请求。甚至还有这样一种情况,攻击者为了绕过基于IP地址的验证策略,利用受害者的IP地址来发起他想发起的请求。 2、获知浏览器的状态。当浏览器发送请求时,通常情况下,网络协议里包含了浏览器的状态。这其中包括很多,比如cookie,客户端证书或基于身份验证的header。因此,当攻击者借助浏览器向需要上述这些cookie,证书和header等作验证的站点发送请求的时候,站点则无法区分真实用户和攻击者。 3、改变浏览器的状态。当攻击者借助浏览器发起一个请求的时候,浏览器也会分析并相应服务端的response。举个例子,如果服务端的response里包含有一个Set-Cookie的header,浏览器会相应这个Set-Cookie,并修改存储在本地的cookie。这些改动都会导致很微妙的攻击,我们将在第三部分描述。 作用范围内的威胁:我们按照产生危害的大小将此部分分成三种不同的危害模型。 1、论坛可交互的地方。很多网站,比如论坛允许用户自定义有限种类的内容。举例来说,通常情况下,网站允许用户提交一些被动的如图像或链接等内容。如果攻击者让图像的url指向一个恶意的地址,那么本次网络请求很有可能导致CSRF攻击。这些地方都可以发起请求,但这些请求不能自定义HTTP header,而且必须使用GET方法。尽管HTTP协议规范要求请求不能带有危害,但是很多网站并不符合这一要求。 2、Web攻击者。在这里web攻击者的定义是指有自己的独立域名的恶意代理,比如attacker.com,并且拥有attacker.com的HTTPS证书和web服务器。所有的这些功能只需要花10美元即可以做到。一旦用户访问attacker.com,攻击者就可以同时用GET和POST方法发起跨站请求,即为CSRF攻击。 3、网络攻击者。这里的网络攻击者指的是能控制用户网络连接的恶意代理。比如,攻击者可以通过控制无线路由器或者DNS服务器来控制用户的网络连接。这种攻击比web攻击需要更多的资源和准备,但我们认为这对HTTPS站点也有威胁。因为HTTPS站点只能防护有源网络。
作用范围外的威胁:下面我们还列出了一些不在本论文讨论范围的相关危害模型。对这些危害的防御措施可以与CSRF的防御措施形成很好的互补。 1、跨站脚本(XSS)。如果攻击者能够向网站注入脚本,那么攻击者就会破坏该网站用户会话的完整性和保密性。有些XSS攻击需要发起网络请求,比如将用户银行账户里的钱转移到攻击者的账户里,但是通常情况下,对CSRF的防御并没有考虑到这些情况。考虑到更安全的做法,网站必须实现对XSS和CSRF的同时防御。 2、恶意软件。如果攻击者能够在用户的电脑上运行恶意软件,那么攻击者就可以控制用户的浏览器向那些可信的网站注入脚本。这时候基于浏览器的防御策略将会失效,因为攻击者可以用含有恶意插件的浏览器来替换用户的浏览器。 3、DNS的重新绑定。像CSRF一样,DNS重新绑定可以使用用户的IP地址来连接攻击者指定的服务器。处在防火墙保护内的服务器或者那些基于IP地址验证的服务器需要一个对抗DNS重新绑定的防御方案。尽管DNS重新绑定的攻击和CSRF攻击的意图非常相似,但是他们还是需要各自不同的解决方案。一个简单的解决DNS重新绑定攻击的方案就是要验证主机的HTTP请求header,确保包含有预期值。还有一个替代方案就是过滤DNS流量,防止将外部的DNS名称解析成内部私有地址。 4、证书错误。如果用户在出现HTTPS证书错误的时候还愿意继续点击访问,那么HTTPS能够提供的很多安全保护就没有意义。有一些安全研究者指出了针对这一种情况的威害,但是在本文中,我们假设用户不会在出现了HTTPS证书错误之后继续点击访问。 5、钓鱼。当用户在访问钓鱼网站的时候,在身份验证的时候输入个人信息,钓鱼攻击就发生了。钓鱼攻击现今非常普遍也很有效,因为用户有的时候真的很难区分钓鱼网站和真正的网站。 6、用户跟踪。一些合作网站会利用跨站请求来对用户的浏览习惯建立一个关联行为库。大多数浏览器都通过组织第三方cookie发送来阻止类似的跟踪,但是利用挂站请求,浏览器的这一特性可以被绕过。 三 登录CSRF无论是利用浏览器的网络连接还是利用浏览器的状态,大多数对CSRF的讨论都集中在能改变服务端状态的请求上面。尽管CSRF攻击能通过改变浏览器的状态来对用户在访问可信网站时候造成危害,但是对它的重视程度还是不够。再登陆CSRF攻击里面,攻击者利用用户在可信网站的用户名和密码来对网站发起一个伪造请求。一旦请求成功,服务器端就会响应一个Set-Cookie的header,浏览器接收到以后就会建立一个session cookie,并记录用户的登陆状态。这个session cookie被用作绑定后续的请求,因而也可被攻击者用来作为身份验证。依据不同的网站,登陆CSRF攻击还可以造成很严重的后果。
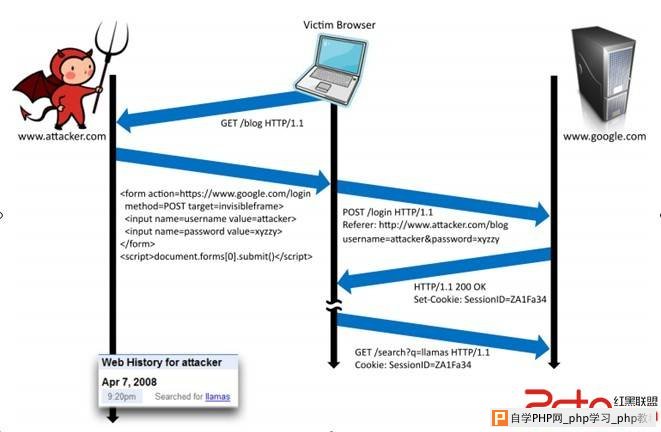
搜索记录:包括谷歌和雅虎等很多搜索引擎允许他们的用户选择是否同意保存他们的搜索记录,并且为用户提供一个接口来查看他们自己的私人搜索记录。搜索请求里面包含了用户的行为习惯和兴趣的一些敏感细节,攻击者可以利用这些细节来欺骗用户,盗窃用户的身份或者窥探用户。当攻击者以用户身份登陆到搜索引擎里,就可以看到用户的搜索记录。如图1. 这样,用户的搜索查询记录就被存储到了攻击者的搜索记录里,攻击者就可以登陆自己的账户随便查询用户的搜索记录。
图1. 登陆CSRF攻击事件的跟踪图。受害人访问攻击者的网站,攻击者向谷歌伪造一个跨站点请求的登陆框,造成受害者被攻击者登陆到谷歌。随后,受害者使用搜索的时候,搜索记录就被攻击者记录下来。
PayPal:PayPal允许它的用户相互之间任意转移资金。转移资金的时候,用户要注册信用卡或者银行账户。攻击者可以利用登陆CSRF来发起以下攻击: 1、受害者访问了恶意商家的网站,并选择使用PayPal支付。 2、受害者被重定向到PayPal并且要求登陆他/她的账户。 3、网站等待用户登陆他/她的PayPal账户。 4、付款的时候,受害者先是登记自己的信用卡,但是信用卡实际上已经被添加到恶意商家的PayPal账户。
iGoogle:用户可以通过使用iGoogle来定制自己的谷歌主页,也包括一些插件。为了易用性,这些插件是“嵌入到iGoogle的”,这也就意味着他们将影响到iGoogle的安全。通常情况下,iGoogle在添加新插件的时候,都会询问用户做出信任决定。但是攻击者可以通过登录CSRF攻击来帮助用户做出决定,从而安装任意的插件。
1、攻击者通过用户的浏览器授权安装一个iGoogle插件(含有恶意脚本),并将插件添加到用户的定制化iGoogle主页。 2、攻击者使用户登陆谷歌,并开一个到iGoogle的框架。 3、谷歌认为受害者就是攻击者,并将攻击者的插件推送给受害者,而且允许攻击者在https://www.google.com域下运行脚本。 4、攻击者现在可以:(a)在正确的URL页面构造一个登陆框(b)盗取用户自动填充的密码(c)在另一个窗口等待用户登陆并读取document.cookie。
我们已经将上述漏洞告知了谷歌,他们已经在两方面来减缓漏洞带来的危害。首先,谷歌已经弃用内嵌的插件并禁止开发者开发类似的插件,只允许少部分比较受欢迎的内嵌插件。其次,谷歌已经开发了私密token策略来防御登陆CSRF(下面将会讨论),但是这个策略只对登陆了的用户才有效。我们预计,谷歌一旦充分测试了他们的防御方案并觉得有效之后,会否认他们的登陆CSRF漏洞。 四 现有的CSRF防御方案一般网站有三种防御CSRF攻击的方案。(1)验证token值。(2)验证HTTP头的Referer。(3)用XMLHttpRequest附加在header里。以上三种方法都在广泛使用,但是他们的效果都不是那么的令人满意。 4.2 Token验证在每个HTTP请求里附加一部分信息是一个防御CSRF攻击的很好的方法,因为这样可以判断请求是否已经授权。这个“验证token”应该不能轻易的被未登录的用户猜测出来。如果请求里面没有这个验证token或者token不能匹配的话,服务器应该拒绝这个请求。 Token验证的方法可以用来防御登陆CSRF,但是开发者往往会忘记验证,因为如果没有登陆,就不能通过session来绑定CSRF token。网站要想用验证token的方式来防御登陆CSRF攻击的话,就必须先创建一个“前session”,这样才能部署CSRF的防御方案,在验证通过了之后,再创建一个真正的session。 Token的设计。有很多技术可以生成验证token。
• session标识符。浏览器的cookie存储方式就是为了防止不同域之间互相访问cookie。一个普遍的做法是直接利用用户的session标识符来作为验证token。服务器在处理每一个请求时,都将用户的token与session标识符来匹配。如果攻击者能够猜测出用户的token,那么他就能登录用户的账户。而且这样做有个不好的地方在于,偶尔用户正在浏览的内容会发送给第三方,比如通过电子邮件直接上网页内容上传到浏览器厂商的bug跟踪数据库。如果正好这个页面包含有用户的session标识符,任何能看到这个页面的人都能模拟用户登陆到网站,直到会话过期。
• 独立session随机数。与直接使用用户的session标识符不一样的是,当用户第一次登陆网站的时候,服务器可以产生一个随机数并将它存储在用户的cookie里面。对于每一个请求,服务器都会将token与存储在cookie里的值匹配。例如,广泛使用的Trac问题跟踪系统就是用的此技术。但是这个方法不能防御主动的网络攻击,即使是整个web应用都使用的是HTTPS协议。因为攻击者可以使用他自己的CSRF token来覆盖来覆盖这个独立session随机数,进而可以使用一个匹配的token来伪造一个跨站请求。
• 依赖session随机数。有一个改进产生随机数的方法是将用户的session标识符与CSRF token建立对应关系后存储在服务端。服务器在处理请求的时候,验证请求中的token是否与session标识符匹配。这个方法有个不好的地方就是服务端必须要维护一个很大的对应关系表(哈希表)。
• session标识符的HMAC。有一种方法不需要服务端来维护哈希表,就是可以对用户的session token做一个加密后用作CSRF 的token。例如, Ruby on Rails的web程序一般都是使用的这种方法,而且他们是使用session标识符的HMAC来作为CSRF token的。只要所有的网站服务器都共享了HMAC密钥,那么每个服务器都可以验证请求里的CSRF token 是否与session标识符匹配。HMAC的特性能确保即使攻击者知道用户的CSRF token,也不能推断出用户的session标识符。
鉴于有充足的资源,网站都可以使用HMAC方法来防御CSRF攻击。但是,很多网站和一些CSRF的防御框架(比如NoForge, CSRFx 和CSRFGuard)都不能正确的实现比较隐秘的token防御。一个常见的错误就是在处理跨站请求的时候暴露了CSRF token。举个例子,一个可信的网站在对另一个网站发起请求的时候附加上了CSRF token,那么那个网站就可以对这个可信的网站伪造一个跨站请求。
案例研究:NoForge.NoForge就是使用服务端保存哈希表的方式来验证用户的CSRF token。它在所有链接和表单提交的时候会附加一个CSRF token,造成这种技术不太完善的原因有以下三个:
1、HTML是在浏览器里动态创建的,而不会被重新加上CSRF token。有些网站是在客户端创建HTML的。比如Gmail, Flickr, 和 Digg都是用JavaScript 来创建表单,而这些表单正是需要CSRF防御措施的。 2、NoForge并没有对指向本站和外站的超链接作区分。如果有一个指向外站的超链接,那么外站可以用请求里面获取到用户的CSRF token。比如,如果phpBB部署了NoForge,那么一旦用户点击了一个连接,连接的站点就可以获取到用户的CSRF token,即使NoForge区分了是本站的链接还是外站的链接,因为Referer 还是会暴露用户的CSRF token。 3、NoForge对登陆CSRF并没有什么效果,因为如果用户已经有了session标识符(登陆了),那么NoForge只会验证CSRF token。尽管这种缺陷是可以修复,但是这也说明了要想正确的实施token验证策略并不是一件很容易的事情。
虽然上述三个原因都是可以修复的,但是这些缺陷都说明了要想正确地实施token验证策略,是很复杂的一件事情。CSRFx 和 CSRFGuard,还有很多网站都说明了这一问题。 4.2 Referer大多数情况下,当浏览器发起一个HTTP请求,其中的Referer标识了请求是从哪里发起的。如果HTTP头里包含有Referer的时候,我们可以区分请求是同域下还是跨站发起的,因为Referer离标明了发起请求的URL。网站也可以通过判断有问题的请求是否是同域下发起的来防御CSRF攻击。 不幸的是,通常Referer会包含有一些敏感信息,可能会侵犯用户的隐私。比如,Referer可以显示用户对某个私密网站的搜索和查询。尽管这些内容对私密网站站长来说是好事,因为他们可以通过这些内容来优化搜索引擎排名,但是一些用户还是认为侵犯了他们的隐私。另外,许多组织也很担忧Referer可能会将内网的一些机密信息泄露出去。
漏洞。从历史上来看,浏览器的一些漏洞使得一些恶意网站有欺骗Referer的价值,尤其是在使用代理服务器的时候。很多对Referer欺骗的讨论都标明浏览器允许Referer可以伪造。Mozilla在Fire-fox 1.0.7里面已经修复了Referer欺骗的漏洞。目前的IE则还有这方面的漏洞,但是这些漏洞只能影响XMLHttpRequest,并且只能用来伪造Referer跳转到攻击者自己的网站。 尺度。如果网站选择使用Referer来防御CSRF攻击的话,那么网站的开发人员就需要决定到底是使用比较宽松还是比较严格的Referer验证策略。如果采用宽松的Referer验证策略,网站就应该阻止Referer值不对的请求。如果请求里面没有Referer,就接收请求。尽管这个方法用的很普遍,但是它很容易被绕过。因为攻击者可以在header里面去掉Referer。例如,FTP和数据URL发起的请求里面就不包含Referer。如果使用严格的Referer验证策略,网站还要阻止没有Referer的请求。这样做主要是为了防止恶意网站主动隐藏Referer,但也会带来兼容性问题,比如会误杀一部分合法的请求,因为有些浏览器和网络的设置默认就是不含有Referer的。所以说这个度一定要掌握好,很多时候取决于经验。我们还会在4.2.1里讨论这个问题。
个案研究:Facebook。纵观Facebook的大部分网站都是使用token认证的方式来防御CSRF攻击的。但是,在Facebook的登陆框部分则使用的是宽松的Referer验证策略。这种方法在面对登陆CSRF的攻击时没有什么作用。举例来说,攻击者可以讲用户从http://attacker.com/重定向到ftp://attacker.com/index.html ,然后再对Facebook发起一个跨站的登陆请求。因为请求来自FTP URL,所以大多数浏览器都不会在请求里包含Referer。
4.2.1 实验 为了评估严格的Referer验证策略的兼容性,我们进行了一项实验来衡量到底有多大概率以及在什么情况下,合法的请求里面不含有Referer。 设计。广告是一个很方便测量浏览器和网络特征的渠道,因此我们可以利用广告作为实验平台。在2008年4月5日到4月8日期间,我们从163,767个独立IP购买了283,945 个广告,分别是两个不同的广告渠道。在渠道A,我们以每千次展示0.50美元的价格购买了网络旗帜广告,关键字为“火狐”,“游戏”,“IE”,“视频”,“YouTube”。在渠道B,我们以每千次展示5美元的价格的间隙广告,关键字为“芭蕾”,“金融“,“花”,“食品”和“园艺”。我们在每个广告渠道上花了100美元,渠道A有241,483点击量(146,310个独立IP),渠道B有42,406点击量(18,314个独立IP)。 广告服务是由我们实验室里的两台主机提供,两个独立的域名是从不同的注册商处购买。每当显示广告时,广告会在接下来的每个请求里面生成一个特定的标识符,并随机选择一台主机作为主服务器。主服务器通过HTTP或者HTTPS协议将客户端HTML发送到我们的服务器,这些HTML能发起一个GET或者POST请求。其中,请求包括提交表单,图像请求和XMLHttpRequests。请求的顺序是随机的并且跟用户的操作无关。当广告通过了浏览器的安全策略之后,就向主服务器发起一个同域的请求,同时向次服务器发起一个跨域请求。每个服务器的成本是400美元,域名是7美元,从一个合法的证书颁发机构获得的90天域验证的HTTPS证书是免费的。服务器根据接收到的网络请求来记录请求参数,包括Referer,User-Agent头,日期,客户端的C类网络,会话标识符。服务器还通过DOM API记录了document.referrer的值,但是不记录客户端的IP地址。为了统计独立的IP地址,服务器利用一个随机产生的KEY而不是记录HMAC的方式,这个KEY会被丢弃。服务器记录的信息不足以单独确定广告的浏览者到底有多少。 伦理。实验的设计遵守两个广告渠道的规则。实验中的行为基本上都是web广告每天的行为,所以都能正常的从广告商那里请求额外的资源,比如图片,音频和视频。尽管我们的广告产生的HTTP请求数目远大于普通的广告,但是我们需要的带宽明显比一个视频广告需要的带宽要小。我们的服务器也像广告商一样,只记录他们所记录的信息。实际上我们的服务器记录的信息明显要比商业的广告商要少,因为我们并不记录客户端的IP地址。
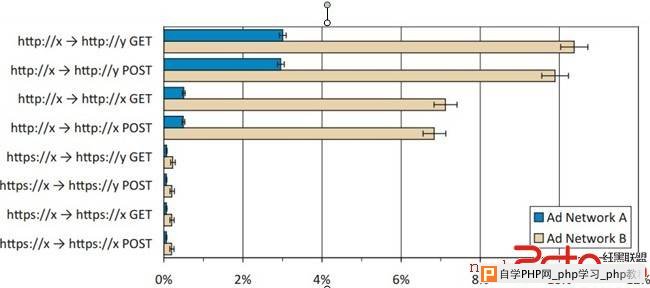
结果。我们已经将结果在图2和图3里总结出来了,我们还发现以下结果只有95%的可信度。
• HTTP方法里, 跨域请求比同域请求不包含Referer头的情况更普遍,而在POST方法(卡方系数= 2130, p值<0.001) 和GET方法(卡方系数= 2175, p值<0.001) 里比较,前者不包含Referer头的情况更为普遍。 • 在不包含Referer头的统计中,HTTP比HTTPS更为普遍,包括跨域POST(卡方系数= 6754, p值<0.001)请求,跨域GET(卡方系数= 6940, p值<0.001)请求,同域POST(卡方系数= 2286, p值<0.001)请求和同域GET请求(卡方系数= 2377, p值<0.001)。 • 在不包含Referer头的统计中,广告渠道B所有形式的请求都比A要更普遍。这些请求形式包括:HTTP跨域POST(卡方系数= 3060, p值<0.001),HTTP同域POST(卡方系数= 6537, p值<0.001),HTTPS跨域POST(卡方系数= 49.13, p值<0.001)和HTTPS同域POST(卡方系数= 44.52, p值<0.001)请求。 • 我们还统计了自定义的header X-Requested-By(参见4.3节)和Origin(见第5章),X-Requested-By大概有0.029%到0.047%的HTTP POST请求,0.084%到0.112%的HTTP GET请求,0.008%到0.018%的HTTPS POST请求和 0.009%到0.020%的HTTPS GET请求里不包含有Referer头。Origin则在与上述相同的请求里都不包含Referer头。
图2. 不包含Referer和Referer不正确的请求(283,945 个结果)。x和y分别代表主服务器和次服务器的域名
讨论。下面有两个有力的证据可以表明在不包含Referer的请求里,通常是来自网络(攻击)而不是浏览器。
1、HTTP请求比HTTPS请求不包含Referer更为普遍是因为,网络代理可以删除HTTP请求里的header,但是不能删除HTTPS请求里的header。当然,在一些企业的网络里,一些HTTPS的终端就是一个网络代理,这种情况下代理可以修改HTTPS请求,但是这种情况是比较罕见的。 2、浏览器在去掉Referer的时候也会去掉document.referrer的值,但是如果Referer是在网络里去掉的话,document.referrer却还在。但是我们发现,Referer去掉的情况比document.referrer去掉的情况要更为普遍。
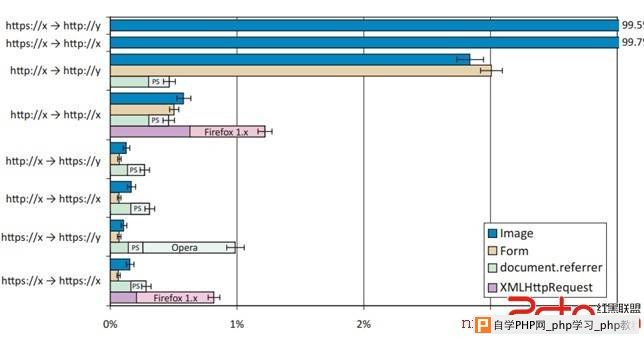
实际上,在实验中,document.referrer值被去掉主要是因为两种特殊的浏览器:PlayStation 3 浏览器不支持document.referrer,Opera去掉document.referrer(但是并不去掉Referer)是为了跨站HTTPS请求。XMLHttpRequest中的Referer被去掉的比例较高是由于Firefox 1.0和1.5中的bug引起的。所有的这些结果都表明只有极少数的浏览器被配置成不发送Referer。 也有证据表明,Referer被去掉是由于涉及到隐私问题,当浏览器把Referer从网站A发送到网站B时,用户的隐私也在被暴露,因为网站B可以通过Referer来收集用户在网站A的浏览行为。相比之下,在同域下发送Referer则不会引起隐私问题,因为网站完全可以通过cookie来收集用户的隐私(也就是完全没有必要通过Referer来收集)。我们还发现,跨站请求比同站请求要更多的阻止Referer,说明由于考虑到隐私的问题,所以才会人为的阻止Referer发送。
由此,我们得出两个主要的结论: 1、通过HTTPS来防御CSRF。在HTTPS请求里,Referer可以被用来防御CSRF。为了实施用Referer来防御CSRF的策略,网站必须拒绝那些没有Referer的请求,因为攻击者可以控制浏览器来去掉Referer。而在HTTP里,网站则不能一味的拒绝没有Referer的请求,因为考虑到兼容性,可能有相当大一部分 (大约 3–11%)用户可能就访问不了网站了。不同的是在HTTPS里,则可以执行严格的Referer验证策略,因为只有很小的一部分(0.05–0.22%)浏览器会去掉Referer。特别需要指出的是,严格的Referer验证策略非常适合用来防御登陆CSRF,因为通常情况下,登陆请求都是通过HTTPS协议发起的。 2、隐私问题。严格的Referer策略是很好的CSRF的防御方案,因为它实施起来很简单。不幸的是,隐私策略可能会阻止此方案的流行。因此,浏览器新的安全性能和新的CSRF防御机制都必须要先解决好隐私问题,才能大规模的部署。
图3. 广告渠道A中不包含Referer和Referer不正确的请求(241,483 个结果)。Opera阻止了跨站的HTTPS document.referrer,Firefox 1.0和1.5由于bug在XMLHttpRequest的时候不发送Referer,PlayStation 3(图中即为PS)不支持document.referrer。 4.3 自定义HTTP header 我们也可以用自定义HTTP头的方法来防御CSRF攻击,因为虽然浏览器会阻止向外站发送自定义的HTTP头,但是允许向本站通过XMLHttpRequest的方式发送自定义HTTP头。比如,prototype.js这个JavaScript库就是使用这种方法,并且增加了 X-Requested-By头到XMLHttpRequest里面 。Google Web Toolkit 也建议开发者用在XMLHttpRequest里增加一个X-XSRF-Cookie头的方法来防御CSRF攻击,其中XMLHttpRequets包含有cookie的值。当然XMLHttpRequets里面的cookie并不需要用来防御CSRF,因为只需要有头部分就足够了。 在使用这种方法来防御CSRF攻击的时候,网站必须在所有的请求里使用XMLHttpRequest并附加一个自定义头(比如X-Requested-By),并且拒绝所有没有自定义头的的请求。例如,为了防御登陆CSRF的攻击,网站必须通过XMLHttpRequest的方式发送用户的身份验证信息到服务器。在我们的实验里,在服务器接收到的请求里面,大约有99.90–99.99%的请求是含有X-Requested-By头的,这表明这一方法适用于绝大多数的用户。 五 建议:Origin字段为了防止CSRF的攻击,我们建议修改浏览器在发送POST请求的时候加上一个Origin字段,这个Origin字段主要是用来标识出最初请求是从哪里发起的。如果浏览器不能确定源在哪里,那么在发送的请求里面Origin字段的值就为空。 隐私方面:这种Origin字段的方式比Referer更人性化,因为它尊重了用户的隐私。 1、Origin字段里只包含是谁发起的请求,并没有其他信息 (通常情况下是方案,主机和活动文档URL的端口)。跟Referer不一样的是,Origin字段并没有包含涉及到用户隐私的URL路径和请求内容,这个尤其重要。 2、Origin字段只存在于POST请求,而Referer则存在于所有类型的请求。 随便点击一个超链接(比如从搜索列表里或者企业intranet),并不会发送Origin字段,这样可以防止敏感信息的以外泄露。 在应对隐私问题方面,Origin字段的方法可能更能迎合用户的口味。 服务端要做的:用Origin字段的方法来防御CSRF攻击的时候,网站需要做到以下几点: 1、在所有能改变状态的请求里,包括登陆请求,都必须使用POST方法。对于一些特定的能改变状态的GET请求必须要拒绝,这是为了对抗上文中提到过的论坛张贴的那种危害类型。 2、对于那些有Origin字段但是值并不是我们希望的(包括值为空)请求,服务器要一律拒绝。比如,服务器可以拒绝一切Origin字段为外站的请求。 安全性分析:虽然Origin字段的设计非常简单,但是用它来防御CSRF攻击可以起到很好的作用。 1、去掉Origin字段。由于支持这种方法的浏览器在每次POST请求的时候都会带上源header,那么网站就可以通过查看是否存在这种Origin字段来确定请求是否是由支持这种方法的浏览器发起的。这种设计能有效防止攻击者将一个支持这种方法的浏览器改变成不支持这种方法的浏览器,因为即使你改变浏览器去掉了Origin字段,Origin字段还是存在,只不过值变为空了。这跟Referer很不一样,因为Referer 只要是在请求里去掉了,那服务器就探测不到了。 2、DNS重新绑定。在现有的浏览器里面,对于同站的XMLHttpRequests,Origin字段可以被伪造。只依赖网络连接进行身份验证的网站应当使用在第2章里提到的DNS重新绑定的方法,比如验证header里的Host字段。在使用Origin字段来防御CSRF攻击的时候,也需要用到DNS重新绑定的方法,他们是相辅相成的。当然对于在第四章里提到的CSRF防御方法,也需要用到DNS重新绑定的方法。 3、插件。如果网站根据crossdomain.xml准备接受一个跨站HTTP请求的时候,攻击者可以在请求里用Flash Player来设置Origin字段。在处理跨站请求的时候,token验证的方法处理的不好,因为token会暴露。为了应对这些攻击,网站不应当接受不可信来源的跨站请求。 4、应用。Origin字段跟以下四个用来确定请求来源的建议非常类似。Origin字段以下四个建议的基础上统一并改进了,目前已经有几个组织采用了Origin字段的方法建议。
• Cross-Site XMLHttp Request。Cross-Site XMLHttp Request的方法规定了一个Access-Control-Origin 字段,用来确定请求来源。这个字段存在于所有的HTTP方法,但是它只在XMLHttpRequests请求的时候才会带上。我们对Origin字段的设想就是来源于这个建议,而且Cross-Site XMLHttp Request工作组已经接受我们的建议愿意将字段统一命名为Origin。 •XDomainRequest。在Internet Explorer 8 Beta 1里有XDomainRequest的API,它在发送HTTP请求的时候将Referer里的路径和请求内容删掉了。被缩减后的Referer字段可以标识请求的来源。我们的实验结果表明这种删减的Referer字段经常会被拒绝,而我们的Origin字段却不会。微软已经发表声明将会采用我们的建议将XDomainRequest里的删减Referer更改为Origin字段。 • JSONRequest。在JSONRequest这种设计里,包含有一个Domain字段用来标识发起请求的主机名。相比之下,我们的Origin字段方法不仅包含有主机,还包含请求的方案和端口。JSONRequest规范的设计者已经接受我们的建议愿意将Domain字段更改为Origin字段,以用来防止网络攻击。 • Cross-Document Messaging。在HTML5规范里提出了一个建议,就是建立一个新的浏览器API,用来验证客户端在HTML文件之间链接。这种设计里面包含一个不能被覆盖的origin属性,如果不是在客户端的话,在服务端验证这种origin属性的过程与我们验证origin字段的过程其实是一样的。
具体实施:我们在服务器和浏览器端都实现了利用origin字段的方法来防止CSRF攻击。在浏览器端我们的实现origin字段方式是,在WebKit添加一个8行代码的补丁,Safari里有我们的开源组件,Firefox里有一个466行代码的插件。在服务器端我们实现origin字段的方式是,在ModSecurity应用防火墙里我们只用3行代码,在Apache里添加一个应用防火墙语言(见图4)。这些规则在POST请求里能验证Host字段和具有合法值的origin字段。在实现这些规则来防御CSRF攻击的时候,网站并不需要做出什么改变,而且这些规则还能确保GET请求没有任何攻击性(前提是浏览器端已经实现了origin字段方法)。 图4. 在ModSecurity里实现origin字段方法来防御CSRF攻击 六 session初始化在session初始化的时候,登陆CSRF只是其中一个很普遍的漏洞。在session初始化了之后,web服务器通常会将用户的身份与session标识符绑定起来。因此有两种类型的session初始化漏洞,一种是服务器将可信用户的身份与新初始化的session绑定到了一起,另一种是服务器将攻击者的身份与session绑定到了一起。 • 作为可信用户的验证。在某些特定的情况下,攻击者可以使用一个可预见的session标识符强制网站开启一个新的session。这一类型的漏洞一般都被称为session定位漏洞。当用户提供他们的身份信息给一个可信网站来验证后,网站会将用户的身份与一个可预见的session标识符绑定到一起。攻击者此时就可以通过这个session标识符来扮演用户的身份登录网站。 • 作为攻击者的验证。攻击者也可以通过用户的浏览器强制网站开始一个新的session,并且强制session与攻击者的身份绑定到一起(第3章已经说明了攻击是怎么完成的)。登录CSRF攻击只是这一类型中的最简单漏洞,但是攻击者还可以有其他的方法强制通过用户的浏览器将session与自己绑定到一起。 6.1 HTTP请求 OpenID:像LiveJournal、Movable Type和WordPress等很多网站都在使用OpenID 协议,建议这些可以使用自签名随机数的方式来对抗回复攻击,但不要将OpenID session与用户的浏览器绑定到一起,因为攻击者可以强制用户的浏览器初始化一个session然后将session与自己绑定到一起。规范中声明了: return_to 这个URL可能被委托方用来在用户的验证请求与验证答复之间建立联系。但是LiveJournal, Movable Type和WordPress都认为这不是必须的,也没有实施它。为了对抗这种攻击,在协议初始化的时候委托方应该生成一个新的随机数,并将它与浏览器的cookie存储到一起,将它包含到return_to参数里。委托方会将在cookie里的随机数与return_to参数里的随机数匹配。这种方法其实与token验证的方法很类似,并且确保了从一开始OpenID 协议的session就能在同一个浏览器上完成。
PHP cookieless(不用cookie的)验证:这种方法被Hushmail 等网站用来防止用户的电脑上还保留有cookie。Cookieless 验证方法是将用户的session标识符存储在请求的参数里面。但是这个方法不能将session与用户的浏览器绑定到一起,因此攻击者可以强制用户的浏览器初始化一个session与攻击者绑定到一起。为了防止这种攻击,网站必须使用另外的方法将session标识符与用户的浏览器绑定到一起。例如,网站可以构造一个长时间的frame,其中包含有session标识符。这种方式是通过将session标识符保存在内存里来将用户的浏览器与session绑定。使用PHP cookieless验证方法的网站通常也会存在session初始化漏洞,会让攻击者可以模仿一个可信的用户。当然,类似的session定位漏洞有很多标准的防御方法,例如,当用户登陆后,网站可以再次生成一个session标识符。 6.2 Cookie重写 漏洞。服务器可以在Set-Cookie字段里用一个Secure flag方式告诉浏览器此cookie只能通过HTTPS协议发送。现金的浏览器都支持这个特性,并且在一些对安全性要求比较高的网站,这个特性通常被用来保护session。但是,这个Secure flag并不能保证完整性。攻击者可以模仿网站通过HTTP向同一个主机发送Set-Cookie字段,并在主机上设立了cookie。当浏览器通过HTTPS向网站发送cookie的时候,网站并没有一个机制来确定cookie是否被攻击者重写。如果这个cookie里面包含有用户的session标识符,攻击者就可以很容易的通过重写用户的cookie来发起一个session初始化攻击。基本上没有网站能够防御这种攻击,因为他们需要客户端提供一个cookie来作完整性验证。但是,有人建议使用浏览器的特性,比如localStorage,它可以弥补这一不足。换句话说,如果网站声称它的应用层session的验证完全跟基于cookie的HTTP层的session无关的话,攻击者可以在验证之前就重写用户的cookie,然后扮演用户登陆网站。尽管安全人员很多年前就知道攻击者可以重写cookie,但是浏览器厂商并没有什么好的对抗办法。厂商考虑到了通过拒绝HTTP请求的方式来对抗cookie重写的攻击,但是这一做法显然不太合理。更糟糕的是,这一方法并不能提供cookie的完整性,因为Cookie 字段本身并不能区分cookie 里是否含有Secure flag。 防御方法。为了不改变现有的cookie字段而就能保护cookie的完整性(是否包含有Secure flag),我们建议浏览器可以在HTTPS请求里面新加一个Cookie-Integrity字段,专门用来检测cookie的完整性状态。这样也是考虑了兼容以前策略的做法。例如 Cookie: SID=DQAAAHQA...; pref=ac81a9...; TM=1203... Cookie-Integrity: 0, 2 当cookie被设置成使用HTTPS协议发送的时候,Cookie-Integrity字段可以在请求里面用来描述cookie字段的索引。如果请求里面的cookie都没有被设置成HTTPS,那么Cookie-Integrity字段的值就为空。对Cookie-Integrity字段的完整性的保护与Secure flag能提供的机密是相辅相成的,并且这样做也具备很好的兼容性,因为服务器会忽略具有无法识别的header的请求。下面是几个设计的建议: 带宽。在每一个HTTP请求中添加内容必然会增加所有网络的延迟,为了节省带宽,我们只在cookie字段里添加cookie的索引值。还有一个建议做法就是添加一个类似cookie字段的副本,命名为cookie2。 多样性。当主机准备建立一个与已有cookie同名的cookie,那么cookie完全可以包含两个同名的cookie。因为在此种情况下,也许Cookie-Integrity字段不能根据cookie名来分辨它们,但是我们可以在cookie字段里面通过索引值来区别它们。 Rollback。在HTTPS请求里面加入Cookie-Integrity字段可以有效的防止rollback攻击。 如果没有Cookie-Integrity字段,并且在不能保证cookie完整性的时候,那么服务器此时也不能确定请求里面的cookie是否具备完整性(假设请求是从一个低版本的主机发出的,即不支持Cookie-Integrity字段)。 同胞域。假设有这样一种情况,example.com分别包含有一个可信的和一个不可信的子域,www.example.com 和 users.example.com。在对example.com设置cookie的时候,不可信的子域就可以注入可信子域的cookie字段。Cookie-Integrity字段并不能防止这种攻击,但是我们可以通过增加一个字段来标识每个cookie的来源(当然这要取决于对带宽和复杂性的考虑)。 我们在Firefox里用202行JavaScript代码添加实现了Cookie-Integrity字段,并增加了一个Integrity flag存储到cookie里面,主要用来记录这个cookie是否被设置成使用HTTPS传输。 七 总结和建议CSRF是当今一个被利用的非常广泛的漏洞。很多网站修复了他们的包括登陆CSRF漏洞在内的CSRF漏洞。基于这篇文章中提到的实验和分析,我们建议网站在不同的情况下使用不同的CSRF防御策略。 • 登陆CSRF。我们建议使用严格的Referer验证策略来防御登陆CSRF,因为登陆的表单一般都是通过HTTPS发送,在合法请求里面的Referer都是真实可靠的。如果碰到没有Referer字段的登陆请求,那么网站应该直接拒绝以防御这种恶意的修改。
• HTTPS。对于那些专门使用HTTPS协议的网站,比如银行类,我们也建议使用严格的Referer验证策略来防御CSRF攻击。对于那些有特定跨站需求的请求,网站应该建立一份白名单,比如主页等。
• 第三方内容。如果网站纳入了第三方的内容,比如图像外链和超链接,网站应该使用一个正确的验证token 的框架,比如 Ruby-on-Rails。如果这样的一个框架效果不好的话,网站就应该花时间来设计更好的token 验证策略,可以用HMAC方法将用户的session与token 绑定到一起。
对于更长远的建议,我们希望能用Origin字段来替代Referer,因为这样既保留了既有效果,又尊重了用户的隐私。最终要废除利用token来防御CSRF的方式,因为这样网站就可以更好的保护无论是HTTP还是HTTPS请求,而不用担心token是否会泄露。
未来的工作。如果使用Origin字段的方法来防御CSRF攻击,网站要注意在处理GET请求的时候不要有什么副作用。尽管HTTP规范里已经这样要求,但是很多网站并没有很好的遵守这一要求。让网站都执行这一要求正是我们未来的工作重点。
CSRF攻击还兴起了一个变种,即攻击者在一个可信的网站嵌入一个frame并引诱用户点击(点击劫持)。尽管从我们的定义上讲,这个并不能算是CSRF攻击,但是他们有一个很相似的地方就在于,攻击者都是利用用户的浏览器来对他信任的网站发起一个请求。防御这种攻击的传统办法都是frame busting,但是这种方法有个问题就是它依赖JavaScript,而JavaScript很有可能会被用户或者攻击者禁用。在这里我们有个建议是,可以在Origin字段里添加一些内容用来描述frame的来源,也就是frame里面的超链接,这样受信任的网站就可以根据frame的来源来决定是拒绝还是接受这个请求。 翻译者:Fireweed原文链接:http://seclab.stanford.edu/websec/Fireweed's blog:http://www.goitcn.com翻译自国外网站转载请注明出处 |
自学PHP网专注网站建设学习,PHP程序学习,平面设计学习,以及操作系统学习
京ICP备14009008号-1@版权所有www.zixuephp.com
网站声明:本站所有视频,教程都由网友上传,站长收集和分享给大家学习使用,如由牵扯版权问题请联系站长邮箱904561283@qq.com