来源:自学PHP网 时间:2019-08-07 16:43 作者:小飞侠 阅读:次
[导读] 简单谈谈Golang中的字符串与字节数组...
|
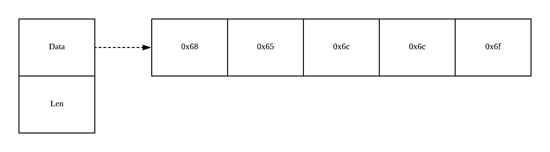
前言 字符串是 Go 语言中最常用的基础数据类型之一,虽然字符串往往都被看做是一个整体,但是实际上字符串是一片连续的内存空间,我们也可以将它理解成一个由字符组成的数组,Go 语言中另外一个与字符串关系非常密切的类型就是字节(Byte)了,相信各位读者也都非常了解,这里也就不展开介绍。 我们在这一节中就会详细介绍这两种基本类型的实现原理以及它们的转换关系,但是这里还是会将介绍的重点主要放在字符串上,因为这是我们接触最多的一种基本类型并且后者就是一个简单的 uint8 类型,所以会给予 string 最大的篇幅,需要注意的是这篇文章不会使用大量的篇幅介绍 UTD-8 以及编码等知识,主要关注的还是字符串的结构以及常见操作的实现。 字符串虽然在 Go 语言中是基本类型 string ,但是它其实就是字符组成的数组,C 语言中的字符串就可以用 char[] 来表示,作为数组来说它会占用一片连续的内存空间,这片连续的内存空间就存储了一些 字节 ,这些字节共同组成了字符串, Go 语言中的字符串是一个只读的字节数组切片 ,下面就是一个只读的 "hello" 字符串在内存中的结构:
如果是代码中存在的字符串,会在编译期间被标记成只读数据 SRODATA 符号,假设我们有以下的一段代码,其中包含了一个字符串,当我们将这段代码编译成汇编语言时,就能够看到 hello 字符串有一个 SRODATA 的标记:
$ cat main.go
package main
func main() {
str := "hello"
println([]byte(str))
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
...
不过这只能表明编译期间存在的字符串会被直接分配到只读的内存空间并且这段内存不会被更改,但是在运行时我们其实还是可以将这段内存拷贝到其他的堆或者栈上,同时将变量的类型修改成 []byte 在修改之后再通过类型转换变成 string ,不过如果想要直接修改 string 类型变量的内存空间,Go 语言是不支持这种操作的。 除了今天的主角字符串之外,另外的配角 byte 也还是需要简单介绍一下的,byte 其实非常好理解,每一个 byte 就是 8 个 bit,相信稍微对编程有所了解的人应该都对这个概念一清二楚,而字节数组也没什么值得介绍的,所以这里就直接跳过了。 字符串在 Go 语言中的接口其实非常简单,每一个字符串在运行时都会使用如下的 StringHeader 结构体去表示,在运行时包的内部其实有一个私有的结构 stringHeader ,它有着完全相同的结构只是用于存储数据的 Data 字段使用了 unsafe.Pointer 类型:
type StringHeader struct {
Data uintptr
Len int
}
为什么我们会说字符串其实是一个只读类型的切片 呢,我们可以看一下切片在 Go 语言中的运行时表示:
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
这个表示切片的结构 SliceHeader 和字符串的结构 StringHeader 非常类似,与切片的结构相比,字符串少了一个表示容量的 Cap 字段,这是因为字符串作为只读的类型,我们并不会直接向字符串直接追加元素改变其本身的内存空间,所有追加的操作都是通过拷贝来完成的。 字符串的解析一定是解析器在词法分析 时就完成的,词法分析阶段会对源文件中的字符串进行切片和分组,将原有无意义的字符流转换成 Token 序列,在 Go 语言中,有两种字面量的方式可以声明一个字符串,一种是使用双引号,另一种是使用反引号: str1 := "this is a string" str2 := `this is another string` 使用双引号声明的字符串其实和其他语言中的字符串没有太多的区别,它只能用于简单、单行的字符串并且如果字符串内部出现双引号时需要使用 \ 符号避免编译器的解析错误,而反引号声明的字符串就可以摆脱单行的限制,因为双引号不再标记字符串的开始和结束,我们可以在字符串内部直接使用 " ,在遇到需要写 JSON 或者其他数据格式的场景下非常方便。 两种不同的声明方式其实也意味着 Go 语言的编译器需要在解析的阶段能够区分并且正确解析这两种不同的字符串格式,解析字符串使用的 scanner 扫描器,它的主要作用就是将输入的字符流转换成 Token 流, stdString 方法就是它用来解析使用双引号包裹的标准字符串:
func (s *scanner) stdString() {
s.startLit()
for {
r := s.getr()
if r == '"' {
break
}
if r == '\\' {
s.escape('"')
continue
}
if r == '\n' {
s.ungetr()
s.error("newline in string")
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}
从这个方法中我们其实能够看出 Go 语言处理标准字符串的逻辑: 1.标准字符串使用双引号表示开头和结尾; 2. 标准字符串中需要使用反斜杠 \ 来 escape 双引号; 3. 标准字符串中不能出现换行符号 \n ; 原始字符串解析的规则就非常简单了,它会将非反引号的所有字符都划分到当前字符串的范围中,所以我们可以使用它来支持复杂的多行字符串字面量,例如 JSON 等数据格式。
func (s *scanner) rawString() {
s.startLit()
for {
r := s.getr()
if r == '`' {
break
}
if r < 0 {
s.errh(s.line, s.col, "string not terminated")
break
}
}
s.nlsemi = true
s.lit = string(s.stopLit())
s.kind = StringLit
s.tok = _Literal
}
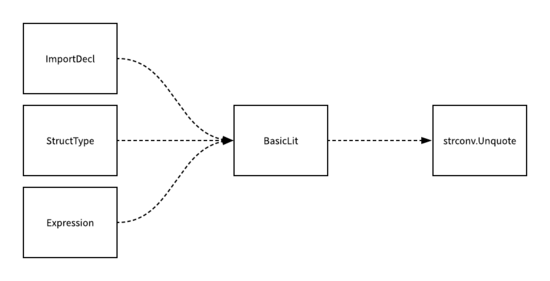
无论是标准字符串还是原始字符串最终都会被标记成 StringLit 类型的 Token 并传递到编译的下一个阶段 ―语法分析,在语法分析的阶段,与字符串相关的表达式都会使用如下的方法 BasicLit 对字符串进行处理:
func (p *noder) basicLit(lit *syntax.BasicLit) Val {
switch s := lit.Value; lit.Kind {
case syntax.StringLit:
if len(s) > 0 && s[0] == '`' {
s = strings.Replace(s, "\r", "", -1)
}
u, _ := strconv.Unquote(s)
return Val{U: u}
}
}
无论是 import 语句中包的路径、结构体中的字段标签还是表达式中的字符串都会使用这个方法将原生字符串中最后的换行符删除并对字符串 Token 进行 Unquote,也就是去掉字符串两遍的引号等无关干扰,还原其本来的面目。
strconv.Unquote 方法处理了很多边界条件导致整个函数非常复杂,不仅包括各种不同引号的处理,还包括 UTF-8 等编码的相关问题,所以在这里也就不展开介绍了,感兴趣的读者可以在 Go 语言中找到 strconv.Unquote 方法详细了解它的执行过程。 介绍完了字符串的的解析过程,这一节就会继续介绍字符串的常见操作了,我们在这里要介绍的字符串常见操作包括字符串的拼接和类型转换,字符串相关功能的主要是通过 Go 语言运行时或者 strings 包完成的,我们会重点介绍运行时字符串的操作,想要了解 strings 包的读者可以阅读相关的代码,这里就不多介绍了。 Go 语言中拼接字符串会使用 + 符号,当我们使用这个符号对字符串进行拼接时,编译器会在类型检查阶段将 OADD 节点转换成 OADDSTR 类型的节点,随后在 SSA 中间代码生成的阶段调用 addstr 函数:
func walkexpr(n *Node, init *Nodes) *Node {
switch n.Op {
// ...
case OADDSTR:
n = addstr(n, init)
}
}
addstr 函数就是帮助我们在编译期间选择合适的函数对字符串进行拼接,如果需要拼接的字符串小于或者等于 5 个,那么就会直接调用 concatstring{2,3,4,5} 等一系列函数,如果超过 5 个就会直接选择 concatstrings 传入一个数组切片。
func addstr(n *Node, init *Nodes) *Node {
c := n.List.Len()
buf := nodnil()
args := []*Node{buf}
for _, n2 := range n.List.Slice() {
args = append(args, conv(n2, types.Types[TSTRING]))
}
var fn string
if c <= 5 {
fn = fmt.Sprintf("concatstring%d", c)
} else {
fn = "concatstrings"
t := types.NewSlice(types.Types[TSTRING])
slice := nod(OCOMPLIT, nil, typenod(t))
slice.List.Set(args[1:])
args = []*Node{buf, slice}
}
cat := syslook(fn)
r := nod(OCALL, cat, nil)
r.List.Set(args)
// ...
return r
}
其实无论使用 concatstring{2,3,4,5} 中的哪一个,最终都会调用 concatstrings ,在这个函数中我们会先对传入的切片参数进行遍历,首先会过滤空字符串并获取拼接后字符串的长度。
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
if l+n < l {
throw("string concatenation too long")
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}
如果非空字符串的数量为 1 并且当前的字符串不在栈上或者没有逃逸出调用堆栈,那么就可以直接返回该字符串,不需要进行任何的耗时操作。
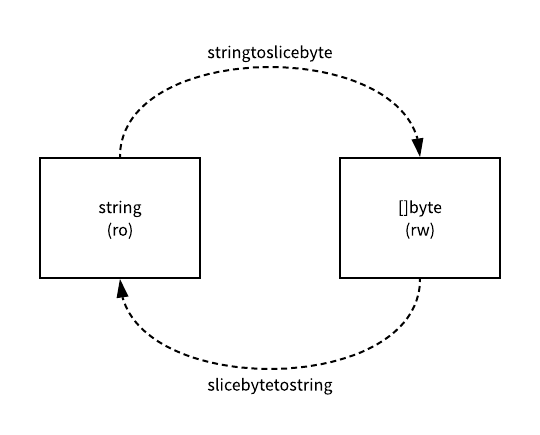
但是在正常情况下,原始的多个字符串都会被调用 copy 将所有的字符串拷贝到目标字符串所在的内存空间中,新的字符串其实就是一片新的内存空间,与原来的字符串没有任何关联。 类型转换 当我们使用 Go 语言做一些 JSON 等数据格式的解析和序列化时,可能经常会将这些变量在字符串和字节数组之间来回转换,类型之间转换的开销并没有想象的这么小,我们经常会看到 slicebytetostring 等函数出现在火焰图中,这个函数就是将字节数组转换成字符串所使用的函数,也就是一个类似 string(bytes) 的操作会在编译期间转换成 slicebytetostring 的函数调用,这个函数在函数体中首先会处理两种比较常见的情况,也就是字节长度为 0 或者 1 的情况:
func slicebytetostring(buf *tmpBuf, b []byte) (str string) {
l := len(b)
if l == 0 {
return ""
}
if l == 1 {
stringStructOf(&str).str = unsafe.Pointer(&staticbytes[b[0]])
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && len(b) <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(len(b)), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = len(b)
memmove(p, (*(*slice)(unsafe.Pointer(&b))).array, uintptr(len(b)))
return
}
处理过后会根据传入的缓冲区大小决定是否需要为新的字符串分配一片内存空间, stringStructOf 会将传入的字符串指针转换成 stringStruct 结构体指针,然后设置结构体持有的指针 str 和字符串长度 len ,最后通过 memmove 将原字节数组中的字节全部复制到新的内存空间中。 从字符串到字节数组的转换使用的就是 stringtoslicebyte 函数了,这个函数的实现非常简单:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
它会使用传入的缓冲区或者根据字符串的长度调用 rawbyteslice 创建一个新的字节切片, copy 关键字就会将字符串中的内容拷贝到新的字节数组中。
字符串和字节数组中的内容虽然一样,但是字符串的内容是只读的,我们不能通过下标或者其他形式改变其内存存储的数据,而字节切片中的内容都是可以读写的,所以无论是从哪种类型转换到另一种都需要对其中的内容进行拷贝,内存拷贝的性能损耗会随着字符串数组和字节长度的增长而增长,所以在做这种类型转换时一定要注意性能上的问题。 字符串是 Go 语言中相对来说比较简单的一种数据结构,作为只读的数据类型,我们无法改变其本身的结构,但是在做类型转换的操作时一定要注意性能上的瓶颈,遇到需要极致性能的场景一定要尽量减少不同类型的转换,避免额外的开销。 相关文章 本作品采用进行许可。 转载时请注明原文链接,图片在使用时请保留图片中的全部内容,可适当缩放并在引用处附上图片所在的文章链接,图片使用 Sketch 进行绘制。如果对本文的内容有疑问,请在下面的评论系统中留言,谢谢。 好了,以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对自学php网的支持。 |
自学PHP网专注网站建设学习,PHP程序学习,平面设计学习,以及操作系统学习
京ICP备14009008号-1@版权所有www.zixuephp.com
网站声明:本站所有视频,教程都由网友上传,站长收集和分享给大家学习使用,如由牵扯版权问题请联系站长邮箱904561283@qq.com