来源:自学PHP网 时间:2014-12-15 15:59 作者: 阅读:次
[导读] 为了处理根据Web标准创作的网页和根据在20世纪90年代末流行的陈旧实践创作的网页,现代的Web浏览器实现了各种不同的引擎模式。本文说明了那些模式是什么以及如何触发它们。...
|
为了处理根据Web标准创作的网页和根据在20世纪90年代末流行的陈旧实践创作的网页,现代的Web浏览器实现了各种不同的引擎模式。本文说明了那些模式是什么以及如何触发它们。
文档范围本文包括的模式转换(mode switching)适用于Firefox和其他基于Gecko的浏览器,Safari、Chrome和其他基于Webkit的浏览器,Opera、 Konqueror、Mac版Internet Explorer、Windows版Internet Explorer和内嵌IE的浏览器。避免提及浏览器引擎的名字,取而代之的是使用该引擎最知名浏览器的名字。 本文着重介绍模式的选择机制,而不是记录每个模式的确切行为。
模式以下是各种不同的模式: 内容类型为text/html的模式text/html内容的模式选择取决于doctype嗅探(doctype sniffing,本文后面有讨论)。在IE8中,模式也取决于其他因素。然而在IE8的默认情况下,那些不在微软提供黑名单上的非局域网(non- intranet)站点的模式取决于文档类型。 再怎么强调每个浏览器中模式精确行为的不同也是不过分的,即使本文中进行了统一的讨论。
内容类型为application/xhtml+xml的模式(XML模式)Firefox、Safari、Chrome和Opera中,application/xhtml+xml HTTP内容类型(不是meta元素也不是doctype!)会触发XML模式。在XML模式中,浏览器尝试给XML文档在规范上的正确处理达到在制定浏览器中的程度。 IE6、7和8不支持application/xhtml+xml,Mac IE5也如此。 基于WebKit的Nokia S60 浏览器中,application/xhtml+xml HTTP内容类型不能触发XML模式,因为在移动的围墙花园(mobile walled gardens)中关注点是对不规范内容的兼容性。(旧式的“移动浏览器”无法使用真正的XML解析器,因为不规范内容已被标记为XML。) 由于没有充分地测试Konqueror,我无法确切说出在这个浏览器中会发生什么。 非Web模式(Non-Web Modes)某些引擎拥有的模式与Web内容无关。为了完整性,它们仅仅在这里被提到。Opera有个WML2.0模式。Leopard上的WebKit有个用于旧式Dashboard widgets的特定模式。 影响以下是这些模式的主要影响: 布局text/html的模式主要是影响CSS布局。例如,表格不继承样式是个怪癖。在某些浏览器的怪癖模式下,盒模型(box model)变成IE5.5的盒模型。本文档没有列举出所有的布局怪癖。 准标准模式(有这种模式的浏览器中)中,仅包含图片的表格单元格的高和标准模式中不同。 XML模式中,选择器有不同的区分大小写行为。此外,用于HTML body元素的特有规则不能应用在那些没有实现最新CSS2.1改变的较旧版本的浏览器。 解析也有一些怪癖影响HTML和CSS的解析且会导致符合标准的网页被错误解析。怪癖布局决定了这些怪癖是否开启。无论如何,了解怪癖模式和标准模式在CSS布局和解析(非HTML解析)上的主要异同是非常重要的。 一些人错误地把标准模式称为“严格解析模式(strict parsing mode)”,其让人误解了浏览器强制执行HTML语法规则和用浏览器评估标记的正确性。情况并非如此。即使当标准模式布局生效时,浏览器依旧会做标签杂烩汤(tag soup,http://en.wikipedia.org/wiki/Tag_soup)修正工作。(在2000年Netscape6发布前,Mozilla的确有用于强制执行HTML语法规则的解析模式。这些模式和现有的Web内容不兼容而被遗弃。) 另一个常见的误解是关于XHTML解析的。通常认为用XHTML doctype得到不同的解析。其实并非如此,内容类型是text/html的XHTML文档所用解析器和HTML文档的是同一个。目前浏览器在意的是文档类型为text/html的XHTML仅是“撒面包丁的标签杂烩汤(tag soup with croutons)”(到处是额外的斜线)。 仅当使用XML文档类型的文档(例如:application/xhtml+xml或xmapplication/)会触发XML模式来解析,这时的解析器完全不同于HTML解析器。 脚本虽然怪癖模式主要是关于CSS的,但也有一些是关于脚本的。例如,Firefox的怪癖模式中,HTML id 属性像在IE一样建立了全局脚本作用域的对象引用。IE8中关于脚本的影响比其他浏览器更值得关注。 XML模式中,某些DOM API的行为彻底不同,因为XML的DOM API行为被定义时不兼容HTML的行为。 doctype嗅探(也叫doctype转换)现代浏览器使用doctype嗅探来决定text/html文档的引擎模式。这意味着模式的选择是基于HTML文档开始的文档类型声明(或缺少)。(这不适于使用XML文档类型的文档。) 文档类型声明(doctype)是SGML的语法伪造,SGML是个旧式的标记框架,HTML5之前的HTML就是依据其定义的。HTML4.01规范中,文档类型声明描述的是HTML的版本信息。尽管名字叫“文档类型声明”且HTML 4.01规范所描述的是关于“版本信息”,文档类型声明并不适用把SGML或XML文档分类为特定类型的文档,即使它看起来像是(因为名字)。(更多内容在附录中) HTML4.01规范和ISO 8879(SGML)都没有说关于使用文档类型声明作为引擎模式转换的任何事情。doctype嗅探是基于观察,在doctype嗅探被设计时,绝大部分的怪癖文档既没有文档类型声明也没有引用旧的DTD。HTML5接受这个事实,且定义了text/html中doctype作为唯一的模式转换。 典型的预HTML5(pre-HTML5)文档类型声明包含(被空白分开)“<!DOCTYPE”字符串,根元素(“html”)的通用标识符, “PUBLIC”字符串,处于引号中的DTD公共标识符,同一DTD的可能系统标识符(URL)和字符 “>”。文档类型声明位于文档的根元素开始标签之前。 选择doctypetext/html下面是创建新的text/html文档时如何选择doctype的简单指南:
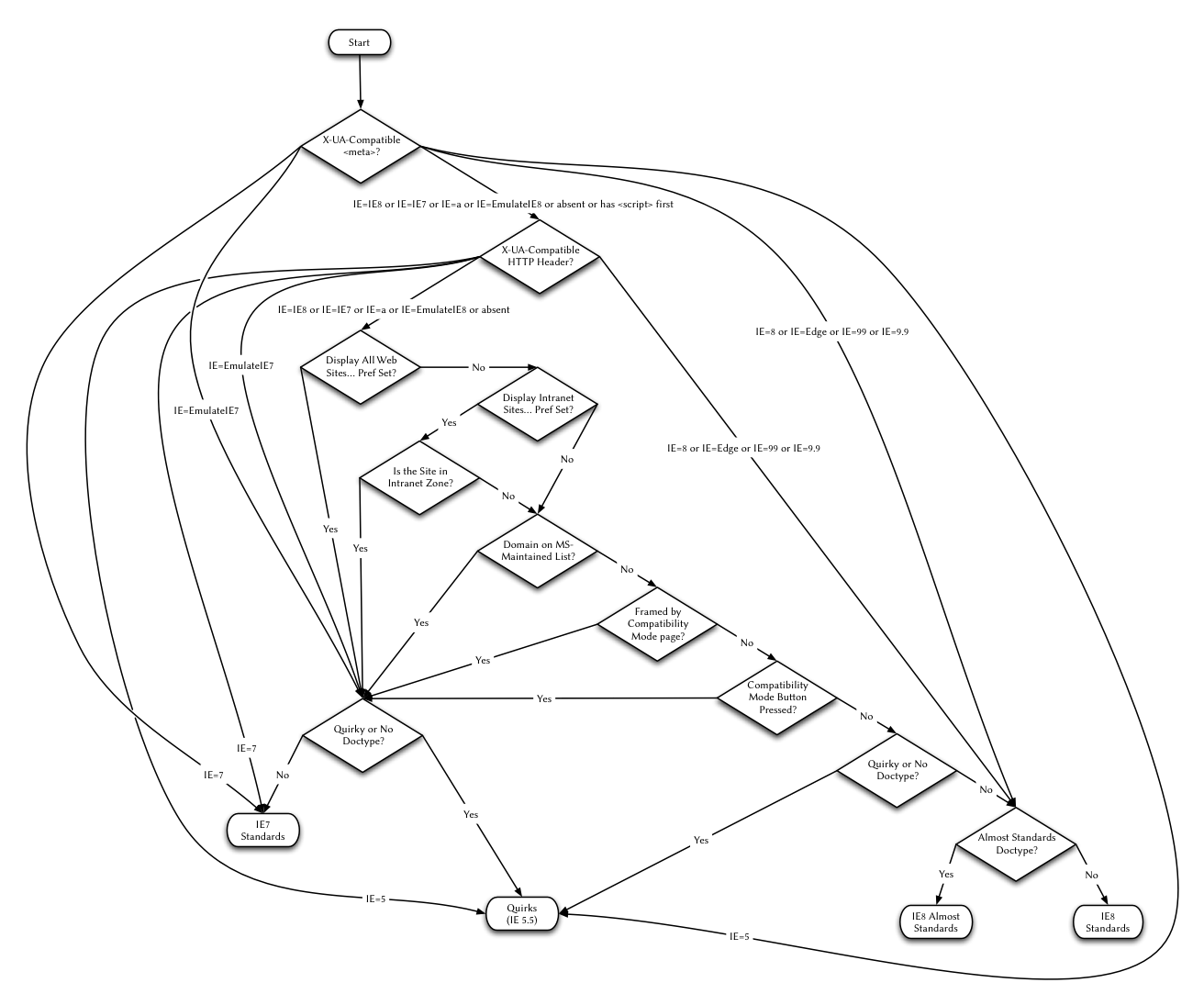
我不推荐任何的XHTML doctype,因为XHTML被用作text/html被认为是有害的。无论如何,如果你选择使用XHTML doctype,请注意XML声明会使IE6(但不是IE7!)触发怪癖模式。 application/xhtml+xml对application/xhtml+xml的简单指南是绝不使用doctype。该方式下的网页不是“严格一致”的XHMTL1.0,但这并不重要。(请看后面的附录) IE8 并发症A List Apart 曾介绍 ,IE8除doctype外会使用基于meta元素的模式转换作为模式选择的因素之一。(请看Ian Hickson、David Baron、David Baron again、Robert O’Callahan 和 Maciej Stachowiak的评论。) IE8有4种模式:IE5.5怪癖模式、IE7标准模式、IE8 准标准模式 和IE8标准模式。模式的选择取决于来自几个方面的数据:doctype、meta元素、HTTP头、来自微软的定期下载数据、局域网域、用户所做设置、局域网管理员所做设置、父框架的模式(如果有)和地址栏兼容视图按钮被用户触发。(对于嵌入该引擎的其他应用,模式也取决于嵌入的应用。) 幸运的是如果出现下列情况,IE8大体上会像其他浏览器一样使用doctype嗅探:
上述除两个关于X-UA-Compatible的情况外,IE8像IE7一样执行doctype嗅探。IE7仿真( IE7 emulation)叫兼容视图。 在 X-UA-Compatible 情况下,IE8的行为和其他浏览器完全不同。想看本页的附录或PDF和PNG格式的流程图。 不幸的是,没有 X-UA-Compatible的HTTP头或meta标签,即使使用了合适的doctype,IE8让用户无意间使页面从IE8的标准模式降到IE7模式,这是一种仿真的IE7标准模式。更糟糕的是,局域网管理员也可以这么做。微软也可以把你所用的所有域名到列入黑名单。 为了对付这些影响,doctype是不够的,你需要X-UA-Compatible HTTP头和meta标签。 下面的简单指南是针对已经有doctype在其他浏览器触发标准模式或者准标准模式的新的text/html文档如何选择X-UA-Compatible HTTP头或meta标签的:
相关链接
补遗:对XML的实现者和规范作者的恳求请不要把doctype嗅探带到XML。 doctype嗅探是用签杂烩汤似的方法解决一个标签杂烩汤问题。doctype嗅探是在HTML4和CSS2规范发布后设计的一种试探方法,它从文档中区分出过时文档以符合其作者可能期望的行为。 偶尔有人建议在XML上使用doctype嗅探来调度不同的处理、识别正在使用的词汇表或激活特性。这是个坏主意。调度和词汇表识别应该是基于名字空间的,而特性激活应该是基于明确的处理指令或元素。 良构(well-formedness)的整个思想是介绍允许XML的无DTD解析,且推广无doctype文档。在正式情况下,两个XML文档有相同的规范形式且应用不同地处理它们(且不同之处并非因为没有选择处理外部实体),这个应用或许被破坏了。在实践情况下,如果两个XML文档导致同样的内容被报告(qnames忽略)给SAX2内容处理器且应用不同地处理文档,这个应用或者被破坏了。考虑到作为 Web作者无法相信每个人都会使用解决额外实体的XMLprocessor来解析其页面(即使一些浏览器看起来这样做,因为它们会映射一定公共的标识符到一个有删节的定义实体的DTD),插入doctype到XML中用于Web是毫无意义的且通常会导致货运崇拜(cargo cultish)习惯。(您仍然使用W3C验证器的DTD覆盖功能来对一个DTD进行验证,虽然W3C验证器会说结果仅仅是暂时有效。或更好的是,你可以用放宽NG验证,它不会污染模式引用的文档。)为了嗅探而要求doctype是非常愚蠢的,即使那是在HTML实践中的解决方法。 此外,当低级别的规范定义两个相等的东西时,高级别的规范不应该尝试给它们不同的含义。请考虑<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">。如果删除公共标识符,依旧指定了同样的DTD,因此doctype <!DOCTYPE html SYSTEM "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">表示和前面的doctype一样。应该不同地嗅探它们么?可以进一步理论。假设复制给example.com一个叫foobar.dtd的DTD:<!DOCTYPE html SYSTEM "http://example.com/foobar.dtd">。这该如何嗅探?应该是同一个意思。甚至整个DTD可以贴在文档中。 换句话说,如果有#include “foo.h”,你不应该给名字foo.h绑定任何black magic,因为它应该允许复制foo.h的内容到文档中或复制foo.h到bar.h中且表示#include “bar.h”。 我不担心HTML和SGML构造相同的参数的原因是Web浏览器不会使用真正的SGML解析器去解析HTML,所以我认为伪装成SGML进行处理是没有用的。无论如何,如果你还不相信,请看W. Eliot Kimber关于此事的文章 comp.text.sgml 附录:text/html中一些doctype的处理方式下表中,怪癖模式、标准模式和准标准分别表示为Q、S和A。当浏览器仅有两种模式时,如果表格单元格的行高和Mozilla的标准模式表现一致时,标准模式标记为“S”,如果表格单元格的行高和Mozilla的准标准模式表现一致时,则标记为“A”。 请注意使用XML内容模型提供服务的XHTML在XML模式下渲染。 本表的目的并不是说表中所有的doctype都是新建页面的合理选择。本表的目的是为了展示我的推荐是依据什么样的数据。 下列的简写符号是用于列标题:
历史记录Moziila的doctype嗅探代码在2000年10月、2001年9月和2002年6月有大幅度的修改。本文档描述的Mozilla(和 Netscape 6.x)建立的状态可以自2000.10.19起在ftp.mozilla.org上看到。本文档未涉及Mozilla M18(和Netscape 6.0 PR3)中的doctype嗅探的工作方式。Safari的doctype嗅探代码自第一个公开的测试版起也有大幅度的修改。本文档不包括比版本V73也叫0.9更早的行为。 Konqueror3.5之前的doctype嗅探代码似乎来自于Safari的很早的一个版本。Konqueror现在和Safari匹配,其doctype嗅探代码来自Mozilla。 从表中可见,Opera的doctype嗅探正由规律的从类似IE向类似Mozilla转变,虽然Opera9.5和9.6在倒退的路上。同时,Opera怪癖模式的布局行为已从仿效IE6的怪癖模式转换到Mozilla的怪癖模式。 附录:IE8的模式选择
鸣谢感谢Simon Pieters、Simon Pieters和Anne van Kesteren帮助我改正了各种Opera版本的模式表和他们的评论。感谢Simon Pieters制作了另一份IE8的流程图。 |
自学PHP网专注网站建设学习,PHP程序学习,平面设计学习,以及操作系统学习
京ICP备14009008号-1@版权所有www.zixuephp.com
网站声明:本站所有视频,教程都由网友上传,站长收集和分享给大家学习使用,如由牵扯版权问题请联系站长邮箱904561283@qq.com
{kind=link}